

Correction, because nobody else wanted to maintain it.
And this has started to become an anti-AI culture war thing, with many of the bugs attributed angrily to AI being bugs that have existed in the code for years.
For those who don’t know, “tridge” is legendary.
He casually reverse engineered Microsoft’s SMB protocol, creating Samba, back when windows file sharing was a key part of Microsoft’s lock in. He also isn’t just the maintainer of rsync, he invented the algorithms it uses. People who worked with him consider him a genius and a guru.
How much you want to bet he’s just bombarded by the “ai security reports arms race” I saw on here a couple days ago, where people use LLMs to find security holes in open source projects (likely a form of ‘fuck the dev’ training)? I mean, for hundreds of reports to come in, some of which I’m sure are legitimate, is overwhelming to a team… and he’s just one dude.
Edit. Looks like I may have been right. User Chairman Meow posted an excerpt from Discord that basically says that. Even legends get lonely, it seems.
Yep. A solo dev working on a project. Legitimate security flaws found by people who don’t know much of anything about coding, but can prompt an LLM. They don’t even understand the bugs they’re submitting, so if he has questions they can’t help.
His choice is either to spend all of his free time trying to patch these bugs, or to look for help. It’s very hard to find help as a solo dev on an unsexy but essential tool. So, he turned to LLMs to help. And, who knows, maybe he’s able to use them slightly more responsibly than other devs. But, LLMs almost inevitably lead to their own bugs because LLMs are always confident, and are designed to produce something that looks as much as possible like real working code, but without any actual thought or analysis behind them.
Which makes it all the more disturbing that he has turned to slopmachines.
If you read the discord chat logs, it makes sense. He’s being bombarded by security vulnerabilities discovered via LLMs, from people who barely know how to code and can’t even explain the flaw that their LLM discovered. He’s a solo maintainer, and his choice is either to leave these security vulnerabilities open, or to turn to LLMs to try to keep up with the need for patches.
I don’t think he made the right choice, but I think he’s probably a much better programmer than me.
I don’t think he made the right choice, but I think he’s probably a much better programmer than me.
I’m a senior dev that works with LLMs these days and been running dozen people teams before and reading slop code is a skill that needs to be built through months/years of work no matter how good of a programmer you are - it’s a different skill set.
This is about to be a big thing. LLMs are very good at finding exploits and creating scripts to exploit them. Now a script kiddy is much more powerful. Companies are trying to figure out how to respond. Red Hat’s Project Lightwell is one such project.
You may not like it, but this is what 10x productivity looks like.
Move fast and break things. Features over stability.
Makes sense for a lean startup. Not so much for a widely used utility for backing up important data.
This is negative productivity. It worked before, and now it doesn’t.
But when it worked there was no work being done. The repo just stayed there, working. Doing nothing.
A few LLM commits have kickstarted the process of a lot of people checking their rsync versions, choosing the correct one. And so on. That is work that wasn’t being done before, and now it is done thanks to LLMs. Truly a wonder of our times.
Reminds me of that Douglas Crockford talk on managers. I’ll see if I can dig it up.
I wonder what he thinks about LLMs.
Okay, I imagine that using an LLM is like having several Tasmanian Devils on your team.
Just gonna copy what tridge said:
bottom line is if you want to be useful then pick holes in the test suite, find things it doesn’t cover, find interactions between options it doesn’t pin down, report those and offer fixes for that.
Why ask for forks or alternatives?
B-but… I want to RAGE against the machine, not work!
rsync is thirty years old. It has been mature and reliable. But now we’re victim-blaming someone that hasn’t (yet) cleaned up somebody else’s mess?
It’s FOSS, the author doesn’t owe you anything.
That’s quite a strawman you’ve framed, or at best a non sequitur.
I wonder about the timing of this. I just got a backup NAS out at my mom’s house some miles away and for one or two beautiful days I was sending Rsync differential backup jobs through the vendor interface for backups over Wireguard. The NAS is still on my network over WG, comes back up in that way after a reboot…but for the last week, those backup jobs just break with a useless error. I haven’t had the time to look under the hood at logs but I’ve been assuming this was slopping config on my part cause I’m new at it. But it would almost be a relief if it was just a bad update (before the graver implications of the situation set in on my mind). I wish I had enough background in this stuff to be useful, but I’m just a bystander and a grateful, useless end user.
I guess OpenRsync is the answer now
Switch to openrsync
I still have my Commodore 128 and 512K memory expansion. When modern computers become so grotesquely over bloated that all they do is burn CPU and RAM on running mutually contradictory programs riddled with bugs no one understands, I’ll be there using GEOS…
Good luck running rsync in that, though
Who cares? I have no idea or need of any of that. I don’t even know what it is. I see people around me are basically digital hoarding addicts.
“Who cares” is exactly what we think about your braindead comments regarding a tool you don’t even use. You complain about “bloat”, all while wasting data storage drive space with your whiny, useless comments. You are bloat in human form.
A whole 200 bytes vs you guys storing yottabytes of crap you don’t even understand.
Wherein backups falling consists entirely of one self report of the users self written backup script not working followed by him seeing commit messages indicating usage of ai with zero effort to show work diagnose the cause or bisect to failing commit despite poster being a hobbyist who dabbles in programming.
Trust me bro.
You should try reading the rest of the comments section. It’s not just this one dude.
Completely unjustifiable to complain about something FREE AND OPEN SOURCE
The developer owes nothing to anyone and is CERTAINLY not owed backlash for using the tools available to try and continue to help others
This kind of reaction is how to ensure the death of FOSS projects. It’s bullying, it’s insensitive, and worst of all it helps no one.
“Absolutely no warranty” means you can’t be taken to court if your product is bad, it does not mean “immune to criticism”.
Open source software comes as-is and without warranty but that doesn’t mean you can’t criticize what people are doing in this space… In fact i’d argue it is integral to it.
That framing is missing a lot. Open source software is way more than about using the code. For me, it is not the bugs and quality that concern me most about things like this (though I do have concerns with that too). It’s about the broader issues with LLMs in terms of cooperate power, environmental impact, etc. Calling it out is less about any one project and more about stopping the whole open source ecosystem from spiraling into an LLM-dependent mess. LLMs themselves can easily become the death of FOSS in a broader sense
LLMs flip the power dynamics of development on their head. For starters, the outputs are likely no longer copyrightable in many jurisdictions, which undermines copyleft licenses (rsync is under GPL for example).
The kind of code that LLMs generate also tend to add complexity rather fast where it becomes more and more difficult for any human to understand it. Becoming dependent on LLMs makes development more of a question of computing power rather than effort. Companies will be able to spend more than you. FOSS will not be able to compete nearly as well. It’s also an inherent dependency on big tech companies who will be happy to exploit that the second they can or cut you off it you start to hit their bottom line. Software cannot be free in terms of freedom if modifying it in a reasonable amount of time starts to almost require a tool controlled by someone else
Using “Open Source” (which has somehow become “public weights” to most) / local LLMs are hardly freedom from this either given that they will always be behind given the massive financial costs to make models, unlike traditional software. If you find any advantage or way to reduce resource usage to make a better model, the bigger tech companies will just quickly scale that up far bigger than you can and meet or exceed what you have. It still just as well makes your ability to modify software dependent on the hardware you have. How free is open source software if it becomes increasingly difficult to modify without an expensive GPU?
I recommend demonstrating your values with helpful actions like donating to FOSS projects, forking them, etc
The lack of control and sustainability you’re articulating represents one side of the basic nature of FOSS.
There are no shareholders.
The other side of it is that it’s open source - someone else can pick up from here and do it their way and there’s nothing stopping them or you.
There’s no good reason to go after the developer.
I have worked on open source projects. I cannot fork sheer number of projects going towards LLMs alone. This is a losing proposition. Open source is not an individualistic action. This is a collective action, and we need developers of open source to live the values of open source
someone else can pick up from here
A big point of my comment earlier was that making a project increasingly LLM generated makes it harder for someone to pick up as quickly. A huge amount of complexity can be added insanely fast. In this rsync example, the entire testing system was changed overnight (while generating issues in the process). The projects become harder to work on in general
EDIT: also to add, this still has the issues of not knowing where the un-copyleftable code lies and/or having to rework large portions of the project are if you want to keep that
deleted by creator
actually the dev does owe the community something. I’m sure the dev has enjoyed many fruits of the labor they put into rsync, but most of all are clout and opportunities.
the dev was able to access high profile high paying jobs because of the success of rsync. they were able to become well known enough in the community to speak to large groups about their project and other topics as well. they were given a platform to voice their opinion and rally support behind topics or other projects.
the dev benefited by the good will of the community.
now, the community that the dev worked with, used, to attain the position they currently hold is complaining that something is wrong. the project is broken. the dev has ignored the problems and continues to use the tool causing all the problems.
no. the dev owes us an explanation at the very least.
- why are they leveraging a flawed tool to maintain such an important and integral solution for the entire world?
- why do they ignore the complaints from the community?
- are they willing to hand over development to a new dev or group that will maintain it properly?
No, they don’t. You’re acting like all those benefits you listed are payment or compensation for the work they did. If those serve as compensation, they don’t create a forward obligation. The paycheck you get at work doesn’t entitle your employer to your continued labor.
The community isn’t owed shit for the guy giving them something useful that may have looked good on his resume. It’s entitled as fuck to think you’re owed something because someone built something you found valuable enough that someone else wanted to hire them.To answer your questions:
- because it’s their project and they thought it was the right tool for the job. What answer were you expecting?
- because the community isn’t working on the project.
- probably not.
Seriously. Demanding someone give up control of their personal project because it’s too important for them to run as they see fit, but not important enough to support or help maintain.
Fork it and maintain it yourself. Literally nothing is stopping you. You’re just as equipped as he is, other than not being the inventor of the underlying technology.
Using AI properly is a skill guys it does not come automatically
Also you need to demand it performs regression tests properly.
Honestly popular models are so good these days if it produces wrong result its the fault of the one in front of the screen.
We are not at the point of AGI so dont expect AI to read your mind
You chose to write this
Yes because most people who hate AI dont even know the ABC of AI or that they hate AI for a completely wrong reason. I dont like AI everywhere either but if we continue hating this greatest achievement of 21st century so far unconditionally we will never get to the light
And this
Yess
Also you need to demand it performs regression tests properly.
You think it cares about what you “demand”?
If you ask it to it will
How du you use ai properly?
probably fucks it every night begging for electrogonorrhea.
How do you know?
First you write your requirements properly in a text or a markdown file. It should properly explain what you want and more importantly what you dont want. Then you give that to AI and dont forget to include “ask any number of clarifying questions before we begin”
Next, be prepared to answer all of its clarifying questions. If you dont know you can ask it to suggest recommended option and pros and cons of each approach
Yeah it will take an entire day. Deal with it. If your requirement is not to just create a few pages of html and css it may take upto half day to a full day but once you are clear. Ask it to write specs and plan and it will.
Then when you are happy with the plan it will start building it. At that point you can step off and let it do its thing
I have the problem that I defined coding patterns, eslint rules etc. But at some points it just ignores it.
It seems it just doesn’t have those defined rules available at all times.
You said to explicitly define things that the agent shouldn’t do?
Using Claude code if that matters.
Where do you define it? Do you define it in CLAUDE.md? That thing gets loaded on every conversation so it should pick up.
Ohh and one thing, you are only supposed to put there something that is absolutely necessary. Things like “This project uses Typescript” is absolutely unnecessary because its something claude will auto infer. Something like “Do not push into master branch” should be there. Also as it gets loaded on every conversation, you should keep it short or else your token usage blows up.
You can have something like “YOU MUST STRICTLY FOLLOW GUIDELINES LISTED IN commit_guidelines.md BEFORE YOU RUN ANY GIT COMMANDS” if you feel your CLAUDE.md is getting too large.
But honestly, you should ask CLAUDE itself to write CLAUDE.md with strict and proper guardrails rather than yourself
What is it about LLMs that makes so many devs’ brains melt?
Here it seems like panic in the face of things like the CopyFail/DirtyFrag/Fragnesia/ssh-keysign-pwn stuff.
That if he didn’t let AI ‘fix’ the issues it can find first, then someone will hit rsync with devastating CVEs.
Problem is he saw that the tool was offering to ‘fix’ things that perhaps weren’t quite right and saw a credible proposal to implement fixes, but the fixes were for bugs no one cared about or noticed and weren’t security related, but incurred side effects that people did notice.
If you have a non-security bug that’s been in place since 2019 and the only thing that noticed was an LLM analysis of your codebase, it may be best to let sleeping dogs lie…
Studies have already shown that the moment you start relegating code to LLMs you kinda just start using them as a crutch even if you don’t need them.
Staff Engineer here. Our CTO told us in March two things. One, if we didn’t get on board with AI then we would be unemployable in 3 months and two, we had to use AI for everything. Literally everything. I asked (as a senior engineer of 19 years) if that included simple bug fixes I see that take minutes vs 30+ describing the problem. The answer was “absolutely”. Our budget is $400K /month to Anthropic and we exceeded that 3 weeks into May
Update on this: those people who didn’t incorporate it into their workflow have been let go. Last night they released 1/6th of the staff.
It’s always the damn suits.
Pump those numbers, make them regret the decision.
Also that’s an insane budget for AI.
I’m doing my part!
Unfortunately “doing your part” is making the AI companies look like they have revenue just before IPO.
Yeah until CTOs start to realize that they spent the budget to double the workforce on tokens while producing nothing of lasting value. Nobody profits from LLM code except LLM companies.
That’s my hope anyway…
Our budget is $400K /month to Anthropic and we exceeded that 3 weeks into May
Fucking hell, that’s so much money to burn on management’s AI addiction. Have to wonder how your finance department feels about burning almost half a million a month.
Also, wild that management is telling you that not letting your skills degrade by handing everything off to an AI is what’ll make you unemployable.
They think once the ball is rolling, then they can phase out the humans.
They think that AI usage is like training a junior dev, that it starts out hopeless but over time can operate without the expertise.
They don’t realize that invoking AI doesn’t work that way, that the context window is the only accumulation of anything germain to your codebase, and that the model doesn’t evolve based on that interaction.
So they don’t care about the skills, they want to get to the point where they can toss a prompt into Claude and have it all taken care of, thinking that their employee usage of it somehow accelerates that outcome.
That’s just a handful of enthusiastic interns, except that you aren’t investing in cultivating future talent…
Oh look, finance has a friend in the other company. This is classic corruption: order shit from your friend’s business and pretend it was necessary.
Burn that budget. Make the CFO pull their hair out when they look at expenses vs revenue. For once, bean counters might save us from this BS.
If they’re anything like my company’s executive team, they’re using AI to make their decisions too. They’re being spoonfed the issue isn’t AI underperforming, it’s you.
They’ll soon fire you first before capitulate on the notion their AI implementation sucks.
The bean counters will maximize their personal profit. You think they can’t game the AI bubble?
Gaming the AI bubble is difficult when you’re a customer.
but that would just cause the entire company to implode (scorpion and frog dot jpeg)
400k a month is quite a bit of GPU power. I do not understand why software companies aren’t at least offsetting their Claude usage with open source models running on their own hardware. It seems like a no brainer. Opus is really good but most tasks aren’t that complex and a smaller model will work just as well.
Because no one ever got fired for buying IBM.
Removed by mod
Sometimes I’m sad I quit software development as a job. So much room for malicious compliance with this AI bullshit. And if something goes wrong you can just blame it on the AI you were forced to use. The fun I could have had…
deleted by creator
Ours said the same thing back in December. Our principal engineer said we had to start using the chatbot for all coding.
I’ve tried it but at some point it gets faster for me to do it myself 50% of the time. And some of the other times it’s just flat out wrong. The times it gets it right are great; but I hate feeling like I’m relying on a slot machine for my job.
I just started using it just to commit and for PRs to make it look like I’m using it all the time. Burns tokens and execs can’t tell the difference.
Towards the end of the month I just start generating mindless crap so I don’t get “dinged” for under-using AI.
The rest of the month I always set the model to the most expensive to try to naturally burn through my quota and get marginally less annoyed by the even worse suggestions from the default models.
Since burning through tokens really involves letting it invoke commands, I don’t really burn that much naturally since I don’t like reviewing and approving commands and I’m sure as hell not going to let it just run comands at will.
Removed by mod
People lazy.
Removed by mod
Honestly what happened to language models is a shame. Good tools perverted to try and do every job. LLMs dont really have a place and eat up so much resources with what effects to a okay scaffolding tool in code, and a piece of shit liar everywhere else. I remember seeing this shit being used in medicine almost 15 years ago thinking thats gonna be a cool technology to we expand. It was fucken not.
you saw LLMs being used in medicine almost 15 years ago? was it something else because the the transformer model was invented in 2017
Not LLMs, it was their predecessor neural nets and just language models.
Neural networking has so much potential in so many places, yet of course the industry collectively zoomed in on LLMs specifically and is trying to sell them as a panacea to the world’s problems.
As though a mechanical parrot knows anything about good coding practices, or literally anything outside of mimicking speech patterns.
My theory is it’s because LLM’s could talk directly to the C-suite.
My theory is it’s because LLM’s could suck up directly to the C-suite.
FTFY
I hate to admit it, but you could very well be onto something haha
Well, they’re both fluent in bullshit, so that checks.
The reason labs focus on LLMs is that language is a great substrate for generalization. Good luck trying to one-shot out of distribution problems using classic neutral networks. They’ve tried for decades to make it happen but LLMs surpassed those results in a few years.
Idk. LLMs don’t seem like a good solution because of how many resources they need to train and run compared to specialized models.
I know it’s in bad taste to quote myself but i wrote an explanation of why this isn’t necessarily a bad solution here
I understand that idea, but at the same time @[email protected] has a point.
There’s a good reason why you generally don’t get a CPU to do graphics and why FPGAs are usually only put on dev units.
Specialist hardware is generally much more efficient cost and energy wise than generalist hardware for a given task.
And I imagine that must be true for neural networks too, as that layer of language processing on top of any task naturally can’t be as efficient/performatative as specialist software/networks made for the job.
And I imagine that must be true for neural networks too, as that layer of language processing on top of any task naturally can’t be as efficient/performatative as specialist software/networks made for the job.
Oh yeah definitely, a specialized model for each task would be more efficient on the inference side but can you imagine the cost of training a million specialized models ? For example you could think of natural language processing as it was done before : one model for sentiment analysis, one model for chronological analysis, one model for identifying legal terms etc… need to classify color descriptions in natural language ? Well here you go train another model. A small model (comparatively) but also one you’ll have to re-train if you want to change the task even slightly.
A LLM has the advantage of being able to generalize a lot of different tasks on the same model, including some that are wildly out of distribution (meaning you hadn’t even thought of them and they are not explicitly stated in the training data). So yeah, you pay a big training tax to train one large model, but then it pays off because that same model can perform on a million different tasks.
At least that’s the thesis. I’m not qualified to judge whether it is proving worth it, but that’s the reason why the industry massively shifted towards LLMs.
Almost all of the latest commits on the project now :/
https://github.com/RsyncProject/rsync/commits/master/

+14k SLoC, -6k SLoC, most of it in May. In software that’s mostly “done” and needs nothing else but bug fixes.
LGTM.
No other way to review long patches besides LGTM says only profession that keeps doing that
The slop continue until shareholders value improve















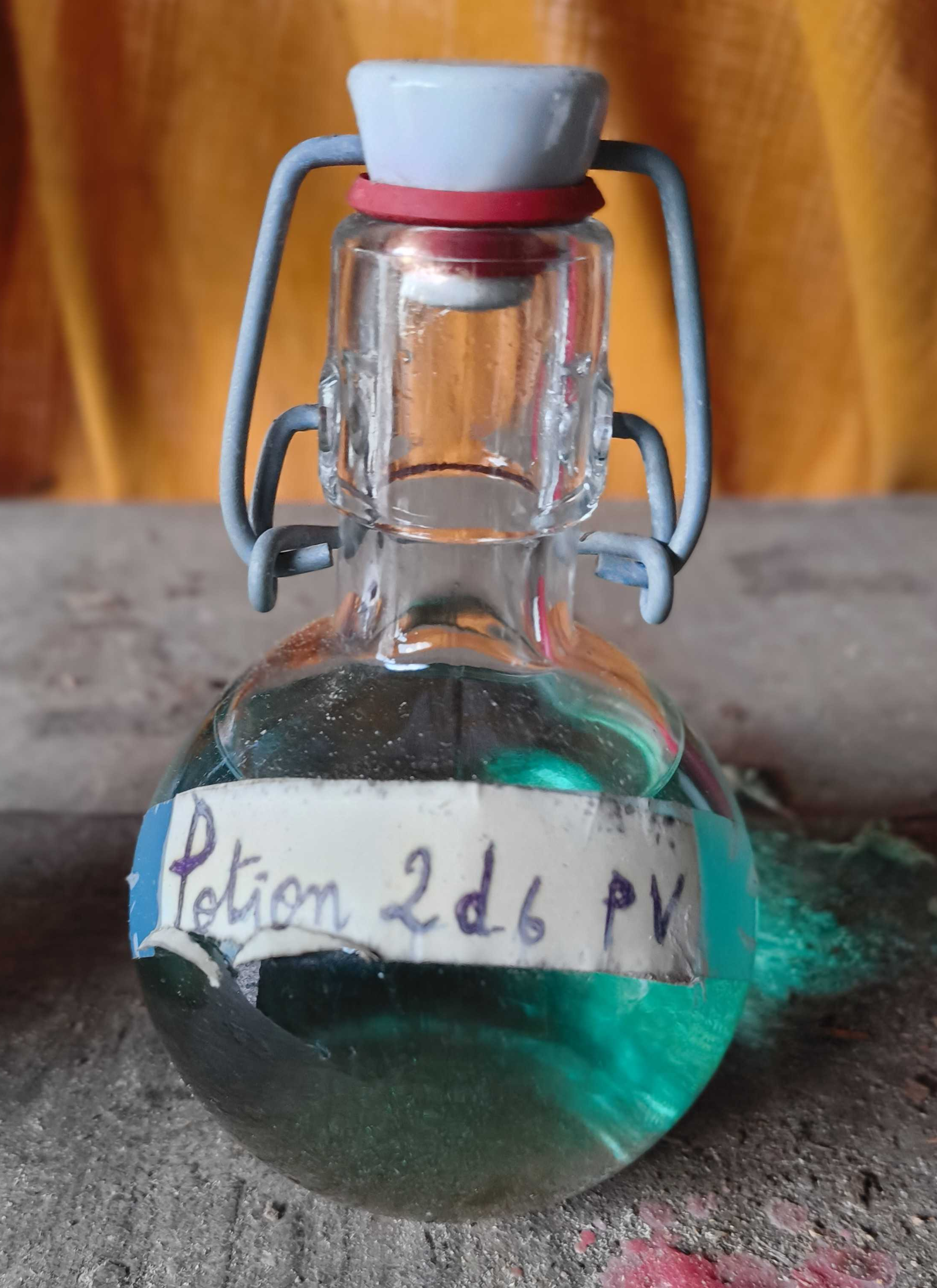

{kind=link}