Neural networking has so much potential in so many places, yet of course the industry collectively zoomed in on LLMs specifically and is trying to sell them as a panacea to the world’s problems.
As though a mechanical parrot knows anything about good coding practices, or literally anything outside of mimicking speech patterns.
The reason labs focus on LLMs is that language is a great substrate for generalization. Good luck trying to one-shot out of distribution problems using classic neutral networks. They’ve tried for decades to make it happen but LLMs surpassed those results in a few years.
I understand that idea, but at the same time @[email protected] has a point.
There’s a good reason why you generally don’t get a CPU to do graphics and why FPGAs are usually only put on dev units.
Specialist hardware is generally much more efficient cost and energy wise than generalist hardware for a given task.
And I imagine that must be true for neural networks too, as that layer of language processing on top of any task naturally can’t be as efficient/performatative as specialist software/networks made for the job.
And I imagine that must be true for neural networks too, as that layer of language processing on top of any task naturally can’t be as efficient/performatative as specialist software/networks made for the job.
Oh yeah definitely, a specialized model for each task would be more efficient on the inference side but can you imagine the cost of training a million specialized models ? For example you could think of natural language processing as it was done before : one model for sentiment analysis, one model for chronological analysis, one model for identifying legal terms etc… need to classify color descriptions in natural language ? Well here you go train another model. A small model (comparatively) but also one you’ll have to re-train if you want to change the task even slightly.
A LLM has the advantage of being able to generalize a lot of different tasks on the same model, including some that are wildly out of distribution (meaning you hadn’t even thought of them and they are not explicitly stated in the training data). So yeah, you pay a big training tax to train one large model, but then it pays off because that same model can perform on a million different tasks.
At least that’s the thesis. I’m not qualified to judge whether it is proving worth it, but that’s the reason why the industry massively shifted towards LLMs.


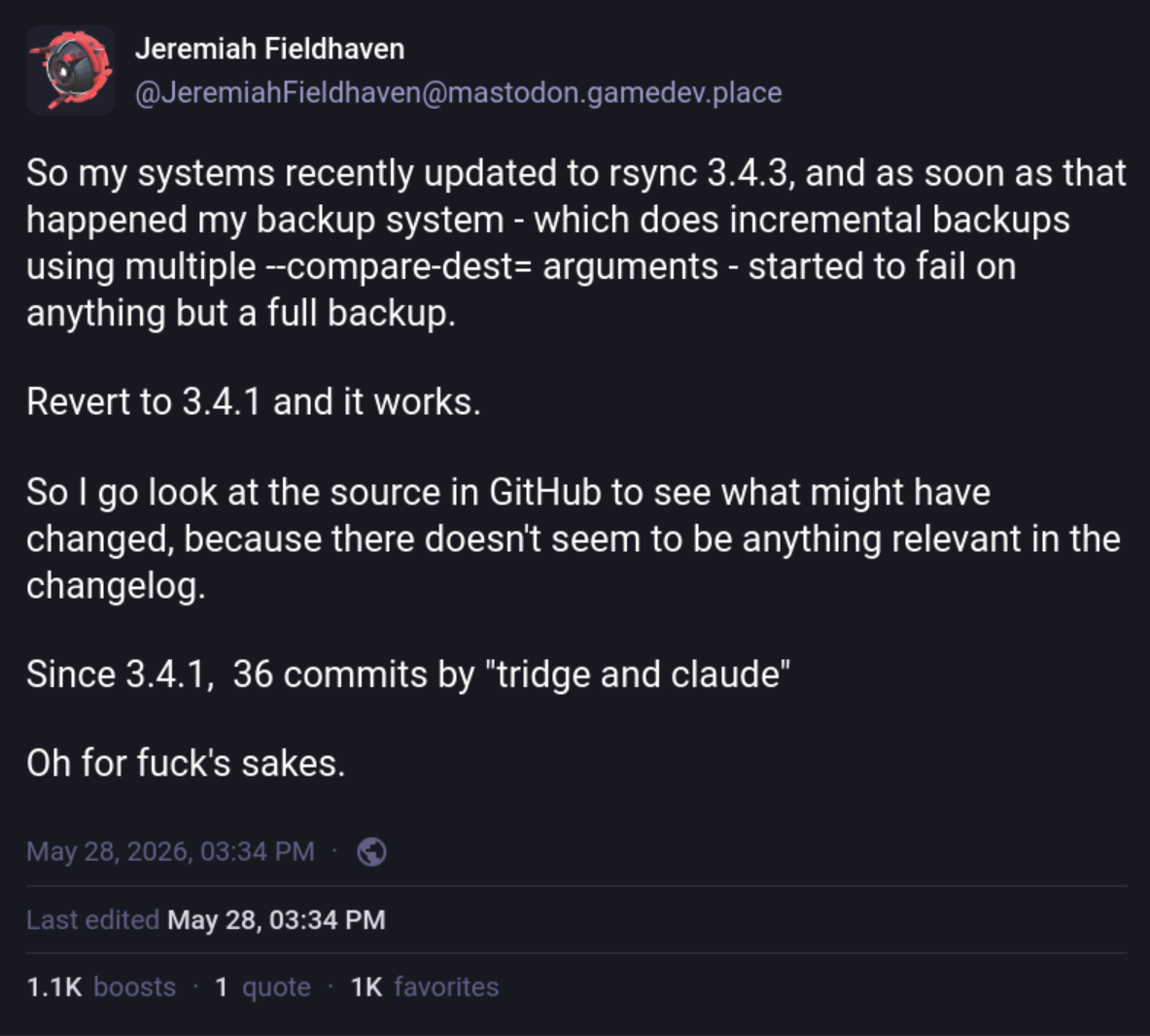{kind=link}
Neural networking has so much potential in so many places, yet of course the industry collectively zoomed in on LLMs specifically and is trying to sell them as a panacea to the world’s problems.
As though a mechanical parrot knows anything about good coding practices, or literally anything outside of mimicking speech patterns.
My theory is it’s because LLM’s could talk directly to the C-suite.
FTFY
I hate to admit it, but you could very well be onto something haha
Well, they’re both fluent in bullshit, so that checks.
The reason labs focus on LLMs is that language is a great substrate for generalization. Good luck trying to one-shot out of distribution problems using classic neutral networks. They’ve tried for decades to make it happen but LLMs surpassed those results in a few years.
Idk. LLMs don’t seem like a good solution because of how many resources they need to train and run compared to specialized models.
I know it’s in bad taste to quote myself but i wrote an explanation of why this isn’t necessarily a bad solution here
I understand that idea, but at the same time @[email protected] has a point.
There’s a good reason why you generally don’t get a CPU to do graphics and why FPGAs are usually only put on dev units.
Specialist hardware is generally much more efficient cost and energy wise than generalist hardware for a given task.
And I imagine that must be true for neural networks too, as that layer of language processing on top of any task naturally can’t be as efficient/performatative as specialist software/networks made for the job.
Oh yeah definitely, a specialized model for each task would be more efficient on the inference side but can you imagine the cost of training a million specialized models ? For example you could think of natural language processing as it was done before : one model for sentiment analysis, one model for chronological analysis, one model for identifying legal terms etc… need to classify color descriptions in natural language ? Well here you go train another model. A small model (comparatively) but also one you’ll have to re-train if you want to change the task even slightly.
A LLM has the advantage of being able to generalize a lot of different tasks on the same model, including some that are wildly out of distribution (meaning you hadn’t even thought of them and they are not explicitly stated in the training data). So yeah, you pay a big training tax to train one large model, but then it pays off because that same model can perform on a million different tasks.
At least that’s the thesis. I’m not qualified to judge whether it is proving worth it, but that’s the reason why the industry massively shifted towards LLMs.