
Honey, I Shrunk The Vids is an overengineered oversimplified system-agnostic frontend for FFMPEG. Built with assistance from Claude, but don’t let that stop you reading - I’ll explain why.
Predendum 6/MAR/26: Yes, I’m using genAI - specifically Claude - to help me build and improve this application. But, I believe I’m using genAI differently than the majority of projects. For one thing, I’m not blindly copy-pasting output and crossing my fingers that it works. I read the output, looking for things I know are wrong, and try to fix it; if I can’t, I ask what I’m doing wrong, and then I fix it. When I encounter errors, I’m reading the error output and if I know how to fix it I do it myself. I’m trying to actually learn, but I do that best by diving in and fixing the mistakes I make. I test informally* on the hardware I have available, which is two Windows PCs, and sometimes my friend with a 2016 Mac will do a test run for me to confirm stuff works. (*by “informally”, I mean I don’t write test cases. I know how, but they’re repetitive and I hate them and I’m not doing it for my personal projects or I’ll end up hating my hobbies.)
My goal in posting my projects is not to have other people audit my code for me, nor do I want kudos or approbation (except for any jokes you see. Those are all me). I’m posting what I’ve got when I’ve got it largely working, in case other people find it useful, and that’s it. I do hope that if people see something I could refactor or conventions I should be adhering to, they’ll drop me a (civil) note about it so I can keep it mind. I appreciate feedback and advice, but I’m not expecting it.
Thanks for reading, I hope you find HISTV useful!
This is a followup to a post I made yesterday, about a silly little Windows application I’d made for batch transcoding files. I wanted something that I could just dump my files onto without having to muck about with Handbrake or Tdarr - post here, for those curious: https://piefed.ca/c/selfhosted/p/568748/honey-i-shrunk-the-vids-a-windows-transcoding-frontend-for-ffmpeg
So I spent today making my silly little Windows application a silly little platform-agnostic application. I rewrote the whole thing in Rust and JavaScript with a webview frontend, and apparently Github lets you compile binaries for quite the range of target platforms, so I have compiled binaries available for Windows, Linux, and Mac (Intel/Apple Silicon). It’s got a dark theme because of course and a light theme because I guess, also it’s themeable because why the hell not. I’m pretty pleased with how it’s coming along - if anyone decides to give it a go, please let me know if you find issues!
screenshots
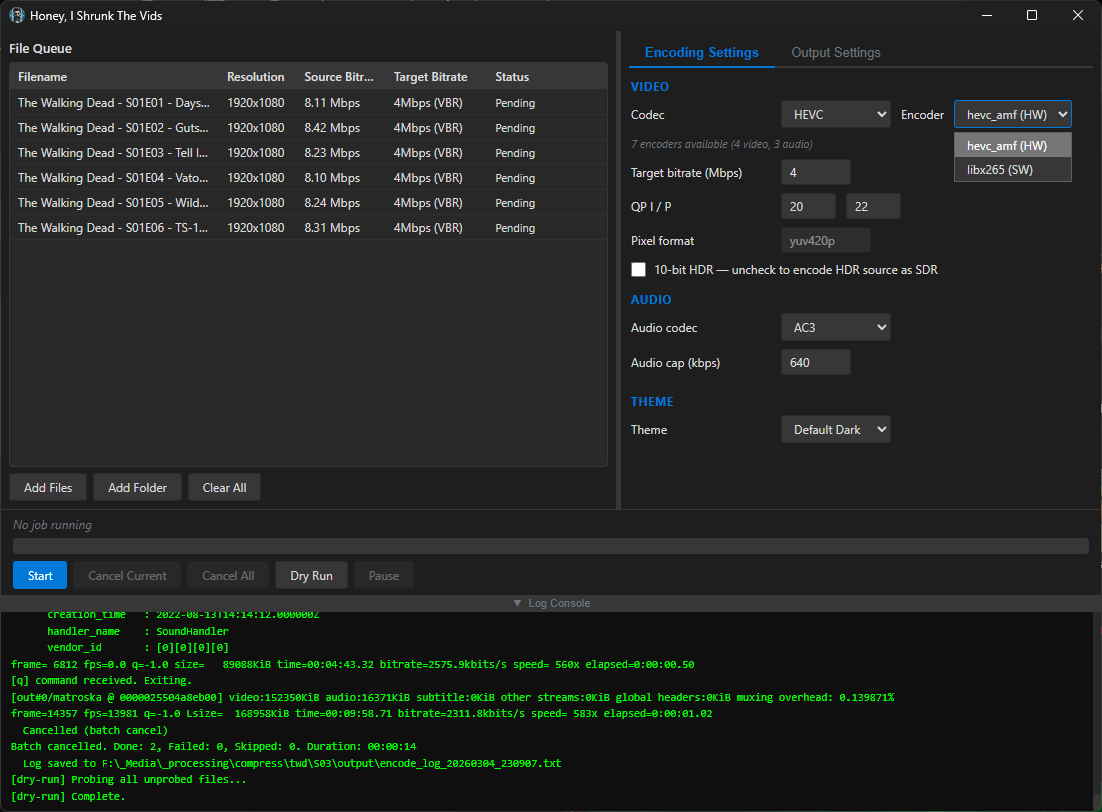
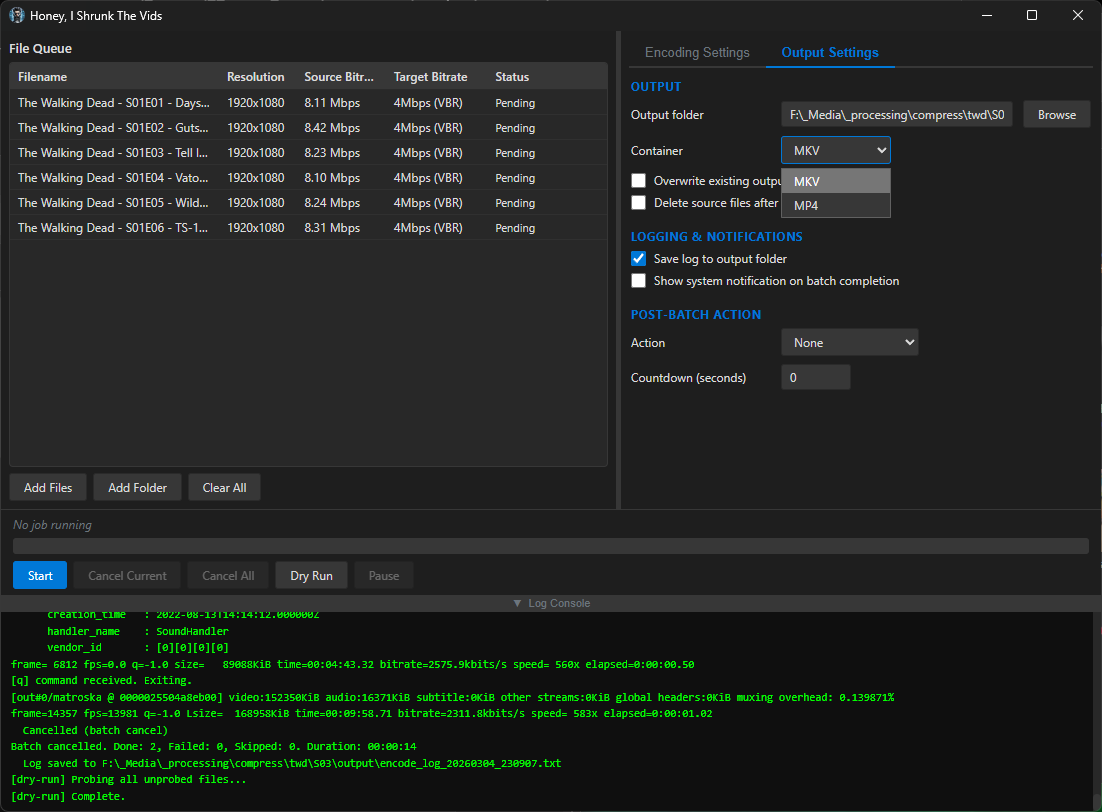
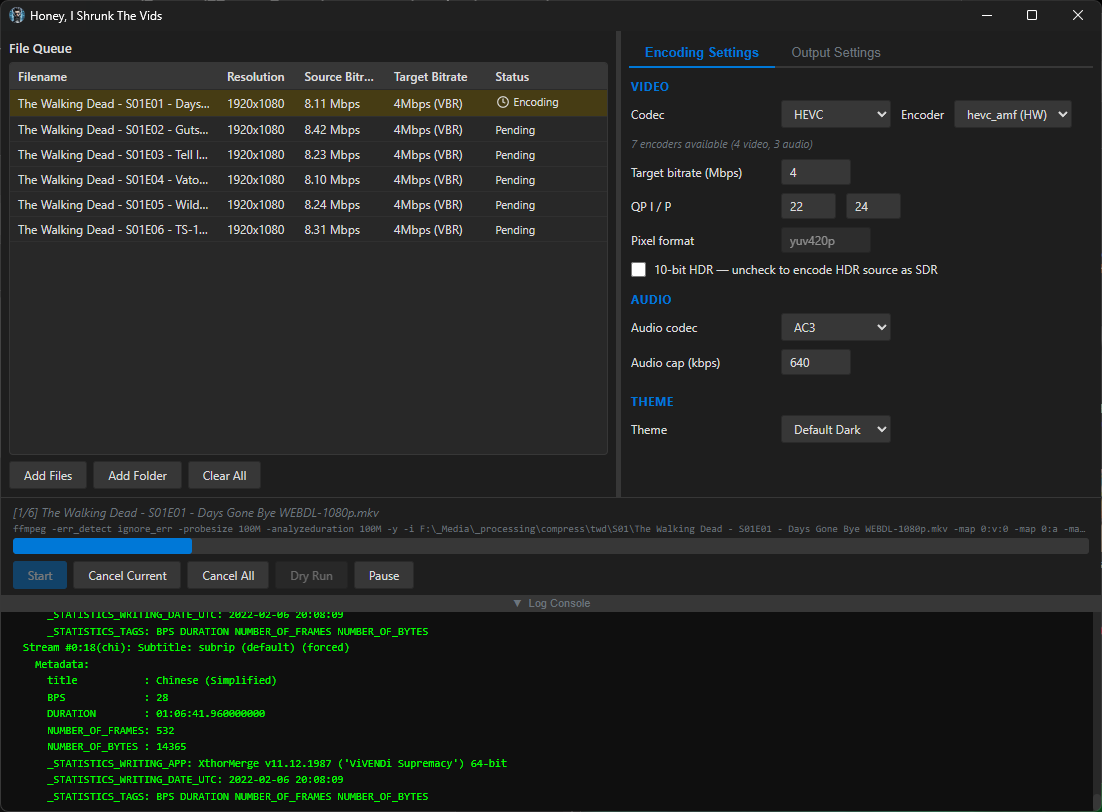
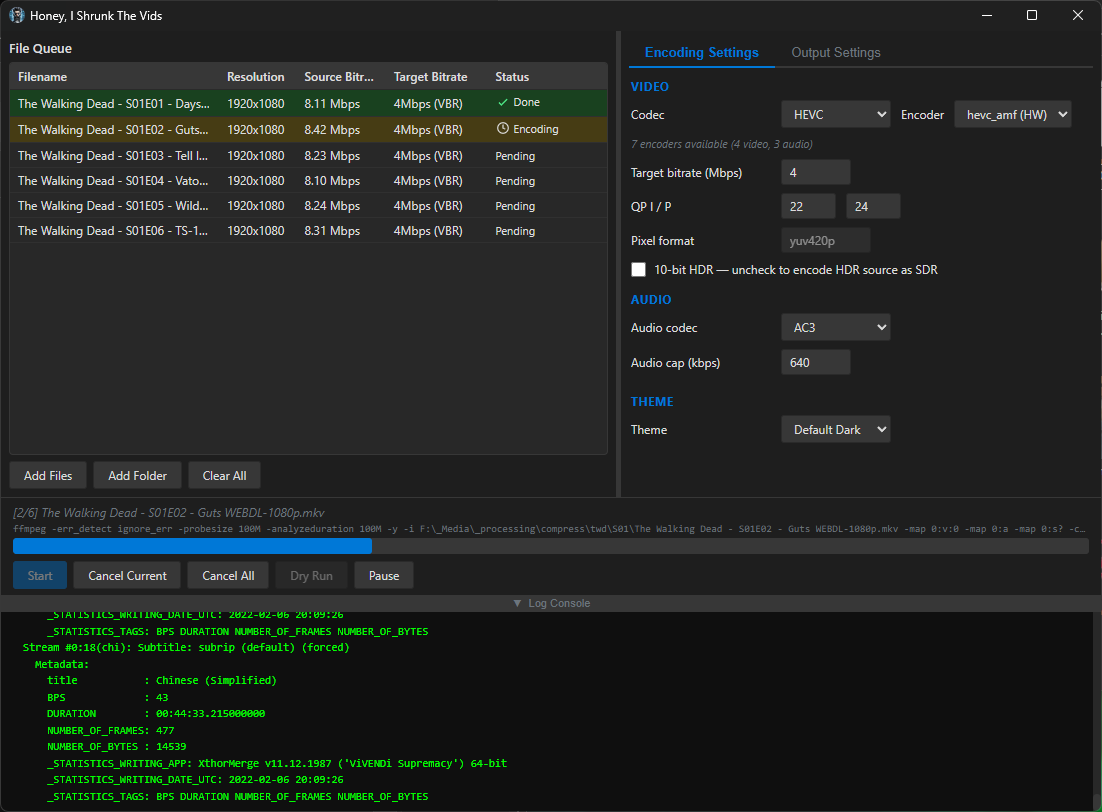
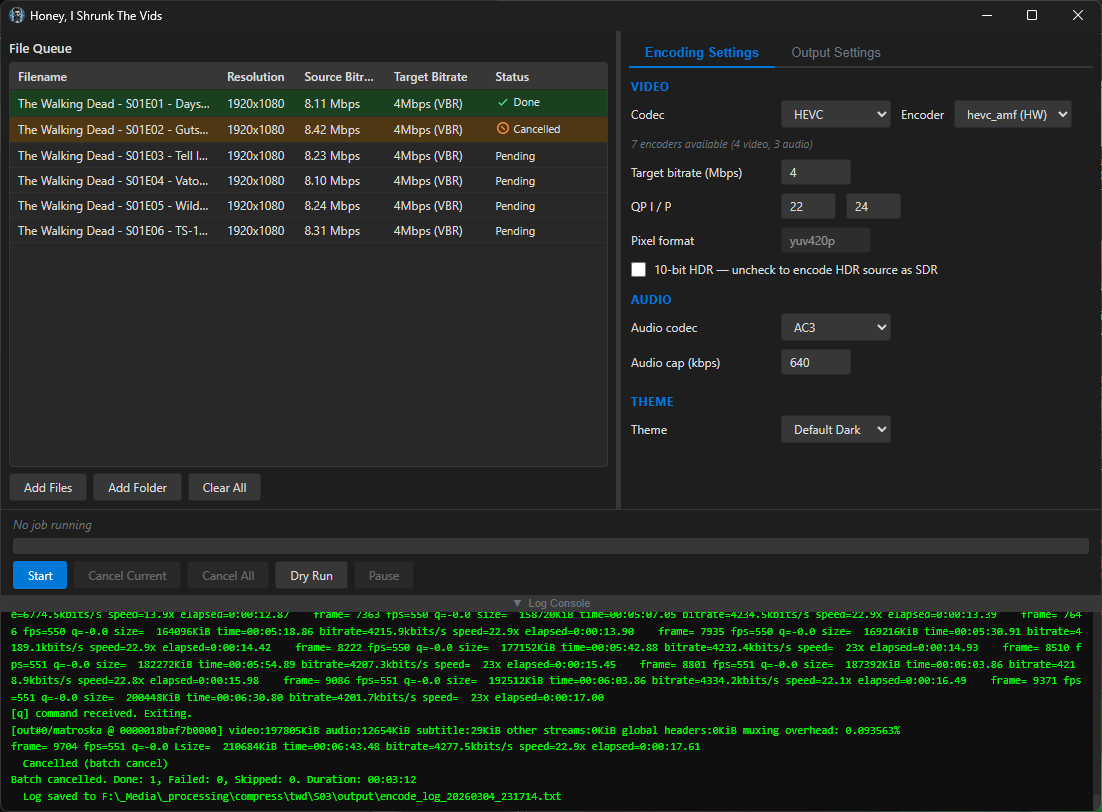
Compiled binaries can be downloaded at https://github.com/obelisk-complex/histv-universal/releases
Missing the ”made using AI, barely tested” disclaimer I see…
Yes, I used Claude to help me build this, but it’s not “barely tested”. The major features all work, and they didn’t at first; I hunted down bugs, caught (some of) the mistakes the AI made, and manually applied fixes so I could be sure I understood what went wrong and why. This was first and foremost a learning experience for me. And I’m actively using this thing to batch transcode my media right now, because my learning experience has resulted in something that works.
If you find issues, by all means let me know and I’ll do my best to fix them. If you’re just here to be a jerk, I’m not interested.
No one is being a jerk here, stop being defensive.
What fixes did you apply. That’s what we want to know. It’s not a trick question.
If you want to present your project, be prepared to explain it. That is completely above board for us to ask.
I agree that the comment was rude. Specifically with the “barely tested” asumption/accusation.
It’s fine, this is healthy discourse we all need to move forward. If we kick out all the vibe coders instead of discussing with them, we will never get them to adhere to any kind of pattern of behaviour.
Really? Literally the only thing they said was
They didn’t ask a question. They just came out swinging, for no reason. You asked three questions, and I’m not going to call you a jerk for it. But just coming in here and making snide remarks? Absolutely being a jerk.
Now, your questions.
No, I didn’t use unit tests. I built this for my own personal use, and tested it on my system and my wife’s with files in a variety of containers encoded at a variety of bitrates with a variety of codecs - random crap we had laying around our hard drives, from the internet, from Steam and OBS records, from our phone cameras. This isn’t commercial software, I’m not asking for donations, and I made the license The Unlicense because I don’t want money or credit for it. I shared it because I got it working and I thought other people might find it useful too. I’m not going to exhaustively test it like I’m taking subscriptions, I hate testing. When I come across an issue, I fix it, and that’s the best I’m offering.
It’s FFMPEG in the backend, and it processes files sequentially. It encodes whatever you put in to HEVC MKV, or H264 MP4. You can set the QP settings for the quality you want. Explain where you expect inefficiency and how I can fix it, and I will.
I’m pushing from a local repo to my Github where it runs a job to compile the binaries for each platform, and to Codeberg where it’s not doing that (so I only have the compiled binaries at GitHub right now).
What fixes did I apply? Many. Some examples would be not successfully detecting available hardware, showing all available encoders rather than only the ones that would work with available hardware, failing to build (so many build failures), window sizing issues, options not showing, hanging on starting a job because the ffmpeg command was getting mangled, failing to find ffmpeg, unable to add files, unable to probe files, packet counting not working so “best guess” settings would result in larger files than the originals, that sort of thing.
And incidentally, the fact that this is a personal project I shared in case someone might find it useful is another reason that coming in here and throwing shade is a shitty thing to do. This isn’t Stack Overflow. If it’s no use to you, move on. If you have constructive criticism, let’s hear it. If you can do it better, go ahead. But why try to make me feel bad about it, because you don’t like the way I built it? I used spaces instead of tabs too, go get the fucking pitchforks.
Again, get off your high horse.
You already know how most self-hosted folks feel about vibe coding, or you wouldn’t have taken immediate offence to the initial comment (which ia valid, btw. You did not mark the project as vibe-coded or ai-assisted.) MARK YOUR PROJECT AS AI-ASSISTED.
I’m looking to replace my cron-timed ffmpeg bash and ash scripts for encoding. Three of the four projects I looked at have double- and triple-work loops for work that should be done once. This seems to be a theme in vibe-coded projects.
Once again, I’m interested in the project, but I have my own thresholds of quality and security. If you can’t handle questions about your project, personal or not, then maybe don’t share it.
Sir/Madam, your feeling are your responsibility, not mine. I did not utter any pejoratives your way. Grow up.
Hey, replying again so you get a separate reply message. So like I said, I went looking for redundant loops and I found quite a few, just like you described. There was also a minor performance issue with the logic that built the FFMPEG argument; it used a lot of unnecessary flags, each of which required fresh memory allocation. That would only be an issue in specific circumstances, like if you were encoding thousands of videos in quick succession… but that’s exactly the kind of issue you were talking about, so I asked for and implemented the fix.
It does seem snappier. I’m pushing 1.0.9, which has the fixes beyond what I found from your comments (I fixed the ones you prompted me to find in 1.0.8). If there’s anything else you’d recommend I look at, I’m all ears.
Nice.
The issues to look for are unnecessary logic (evaluating variables and conditions for no reason), and double sets of variables.
One of the seasoned devs I work with said she encourages coders to transpose work at major inflection points, and this helps all devs gain an understanding of their own code. The technique is simply to rewrite/refactor the code in a new project manually, changing the names of the variables and arrays. The process forces one to identify where variables and actions are being used and how. It’s not very practical for very big projects, but anything under 1000 lines would benefit from it.
Good luck.
That’s very similar to what I’ve been doing 😊 This project I think is on the cusp, a few of the files are over a thousand lines but it’s still kinda manageable. Comparatively, the PowerShell script I started with was far simpler. That one I actually did write most of it because I know how to get stuff done in PowerShell - just needed Claude’s help with the GUI.
Also, I was thinking about your comment on performance when you’re looking at tens of thousands of runs - definitely not my original intent for this, I figured anyone doing that would just use CLI, but it’s totally possible with HISTV. I added an option to put files in /outputs, path relative to the input file, so you totally could just drag a top level folder info the queue, it’ll enumerate the media in all the subdirectories, and hit start. You’d get the transcoded files right next to the originals in your folder structure so they’re easy to find. Useful, I hope, when doing that many jobs.
And thanks to your advice, it’ll do so a lot more efficiently. Like 5-6x lower resource usage, now. I really do appreciate the feedback, it’s exactly the kind of pointers I was hoping for when I posted this. I wish you’d come in to the comments outside my emotional response to someone else :P
I’m 50 yrs old now, but I used to react almost the same way you did, I understand where you’re coming from.
I personally believe LLMs (and AI in general) can be great tools to help along with coding and similar tasks, we just don’t have a very good culture of their use yet.
I’m on a high horse? You’re the one riding in here yelling at me for not conforming to your arbitrary rules I didn’t know about, and defending someone who did nothing but insult me.
No, I don’t know any such thing, I took offense to the implication that there was no effort put into this, and the absolute absence of any constructive criticism whatsoever. And again, I didn’t agree to your rules, and I don’t owe you anything, so take you imperious commands somewhere else, thank you very much.
See, this is something I can actually work with. I’m looking for places that unnecessary probes get spawned for example - there are some that are necessary for the way I want this thing to work, but there’s one just for audio data when previous probes already get that. A useful observation that resulted in an improvement. Thank you.
First of all, I’m going to say this very clearly so maybe it gets through: I am not mad about questions. I am mad about insults and a lack of questions. Thank you for your attention to this matter 🤦 Next: Your thresholds are your responsibility, I didn’t know about them when I built this and I didn’t build it for you, I’m sharing it and you happened to stop by. I appreciate your observations on issues to watch out for when I’m using genAI code, I will be keeping an eye out for duplicated loops and other issues in future projects.
You have issued a few helpful specifics and otherwise roundly shouted at and condescended to me. You have a few things to learn about living in a civil society, based on how you treat strangers who are trying to learn new skills. Grow up.
O-kay…so you chose this route. Not going to read any of these walls, but to answer your initial point, I was merely alluding that it would be nice to declare the use of LLM tools these days.
And I too am a leet-full-stack-vibecoder but I rarely publish any of those tools other than for internal company use, always, ALWAYS, declare that the code is likely not fully verified/tested, and never simply say I did it. The apps work in my environment and test scenarios but might not in yours. I have seen how fragile the code/logic can sometimes be, perhaps not in this case, but who knows. And while things are getting better and better by each LLM release, it does not remove the importance of declaring the tools so people know what to expect.
But of course people tend to publish these with the usual ”look what I made” for some reason… Guess it makes people feel special?
I really need to stick to my rule of taking a day to think before I respond.
So here’s the thing, I understand why people would want me to label my posts as AI-assisted. I’m sure there are a lot of people who just ask the AI to build them a thing, slap it all together, and throw it up on the internet as a finished project, and it’d be exhausting to be looking at the 95th slopbucket of a codebase and realise you’ve been bamboozled again by genAI.
I’m explicitly trying to not be that guy, so here’s what I’m doing. I’ve added a preamble to the post disclaiming this project is AI-assisted, and why I think it’s fair to say I’m doing it differently than most. I’ll add something like that to my other post now, and I’ll include clean it up to include a shorter boilerplate version in future posts. It’s the internet, nobody knows me, so it’s only fair to introduce myself!
If you have any advice or feedback to contribute, I’d genuinely appreciate it - it’s just easier for me to take on board if I don’t have to fight through emotional dysregulation to read it.